
1. Le contexte
Pendant la majeure partie de 2024 et 2025, l'IA pour développeurs fonctionnait comme un système verticalement intégré. L'éditeur, l'agent, le modèle et la facturation venaient du même fournisseur. Cursor proposait une expérience optimisée autour de quelques modèles partenaires. GitHub Copilot était indissociable d'OpenAI. Claude Code, lancé par Anthropic, n'était utilisable qu'avec les modèles Claude. Cette intégration verticale a permis une optimisation fine entre l'agent et le modèle, mais elle a aussi figé le marché : changer de modèle imposait de changer d'outil, donc d'environnement, donc de courbe d'apprentissage.
La sortie de DeepSeek-V4 en avril 2026 a brisé ce modèle, non pas par sa puissance brute — d'autres modèles open-weights l'avaient déjà précédé — mais par une décision de produit beaucoup plus radicale : exposer une API strictement compatible avec le protocole Anthropic.
Concrètement, n'importe quelle requête formatée pour Claude peut être adressée à DeepSeek sans la moindre adaptation côté client. Et cela vaut, en premier lieu, pour Claude Code lui-même.
Le résultat est paradoxal : l'outil de développement le plus avancé d'Anthropic est en train de devenir l'un des principaux véhicules de migration des développeurs vers un modèle concurrent. Les sections qui suivent expliquent pourquoi cette bascule est rationnelle, comment elle s'exécute, et quels sont ses véritables coûts cachés.
2. L'architecture du découplage
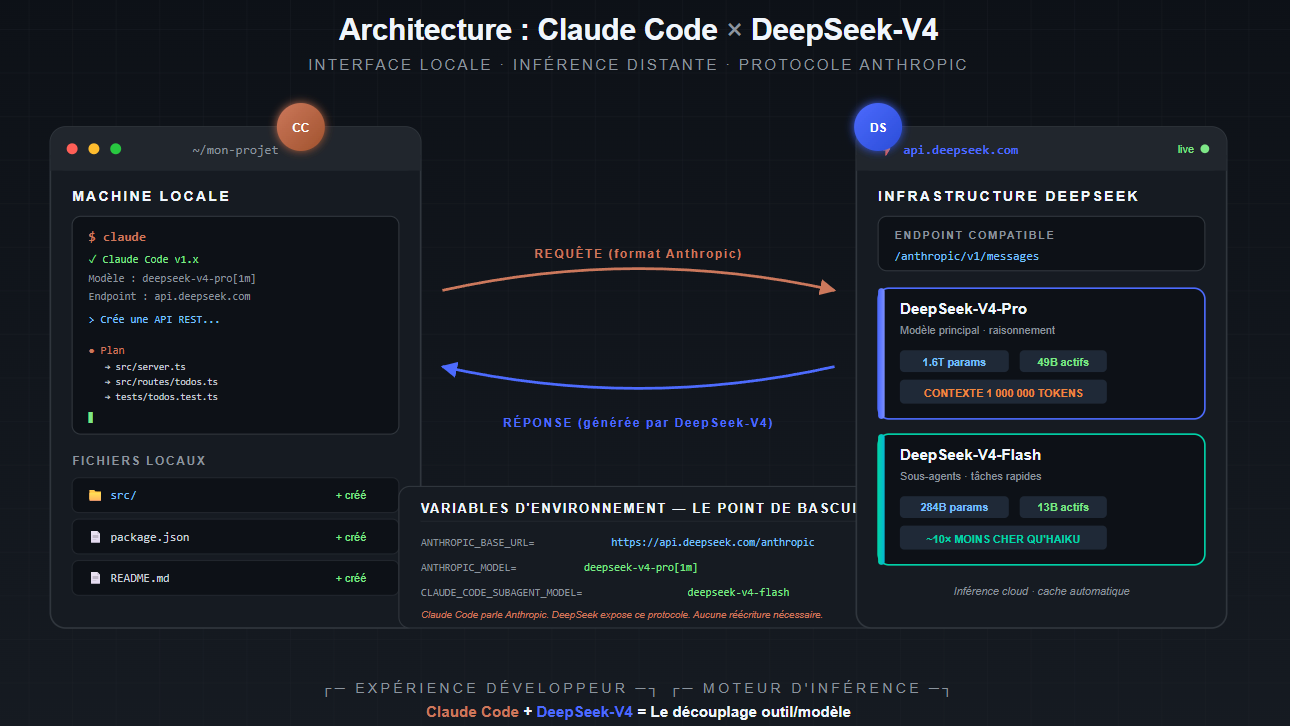
Le diagramme se lit de gauche à droite. À gauche, la machine du développeur héberge Claude Code qui lit, écrit et exécute des fichiers du projet local. Au centre, trois variables d'environnement constituent le seul point de bascule : elles redirigent les appels HTTP que Claude Code adressait à api.anthropic.com vers l'endpoint compatible de DeepSeek. À droite, l'infrastructure de DeepSeek héberge les deux modèles V4-Pro (raisonnement principal, 1,6 trillion de paramètres) et V4-Flash (sous-tâches rapides, 284 milliards), tous deux dotés d'une fenêtre de contexte d'un million de tokens.
Le point essentiel à comprendre est que cette redirection ne nécessite aucune transformation des requêtes. Claude Code envoie son trafic dans le format messages.create({...}) propre à Anthropic, et DeepSeek répond dans le même format. Aucun proxy applicatif, aucune réécriture, aucun adaptateur. La compatibilité est assurée au niveau du protocole lui-même.
C'est cette propriété — l'interchangeabilité au niveau API — qui rend la bascule structurellement différente d'un simple changement de fournisseur. Le développeur conserve l'intégralité de son environnement : commandes, raccourcis, intégrations IDE, gestion du contexte, sous-agents, MCP servers. Seul le moteur d'inférence change.
3. Trois entités distinctes qu'il faut séparer mentalement
Une grande partie de la confusion qu'on observe sur ce sujet vient d'un amalgame entre trois entités qui portent des noms voisins mais qui sont fondamentalement différentes.
Claude désigne une famille de modèles (Opus, Sonnet, Haiku) entraînés et hébergés par Anthropic. Ce sont des poids et une infrastructure d'inférence. On ne les installe pas, on les interroge à distance.
Claude Code désigne un outil de ligne de commande développé par Anthropic. Il s'installe sur la machine du développeur, lit le projet local, propose des modifications de fichiers, exécute des commandes shell, lance des tests et itère sur les résultats. C'est un agent, dans le sens technique : un système qui boucle entre observation, planification et action.
Le protocole Anthropic, parfois appelé "Anthropic API", désigne le format des requêtes HTTP par lesquelles un client (qu'il s'agisse de Claude Code, du SDK officiel ou d'une application tierce) communique avec un modèle. Ce protocole est aujourd'hui implémenté nativement par Anthropic et par compatibilité par DeepSeek, OpenRouter, Fireworks AI, et plusieurs autres fournisseurs.
L'opération décrite dans cet article consiste à conserver Claude Code et le protocole, mais à substituer le modèle. Une analogie utile : Claude Code joue le rôle d'un ORM qui parle SQL standard ; on peut donc le brancher sur PostgreSQL ou sur MySQL sans réécrire l'application.
4. Spécifications techniques de DeepSeek-V4
DeepSeek-V4 se décline en deux variantes, toutes deux disponibles via l'API et dont les poids sont publiés en open source sur Hugging Face.
DeepSeek-V4-Pro est le modèle principal. Il compte 1,6 trillion de paramètres au total, dont 49 milliards activés par token grâce à une architecture mixture-of-experts (MoE). Cette approche permet de bénéficier de la capacité d'un très grand modèle tout en limitant le coût computationnel par requête. La fenêtre de contexte atteint un million de tokens, ce qui permet d'injecter des bases de code complètes ou plusieurs documents techniques volumineux dans une seule requête.
DeepSeek-V4-Flash est conçu pour les tâches à fort volume et faible latence. Avec 284 milliards de paramètres au total et 13 milliards activés par token, il propose un compromis vitesse/qualité optimisé pour les sous-agents et les opérations courtes (recherche dans les fichiers, classifications, transformations simples). Il partage la même fenêtre d'un million de tokens.
Cette architecture à deux modèles correspond exactement à la structure attendue par Claude Code, qui distingue en interne un modèle principal (l'équivalent d'Opus) et un modèle rapide (l'équivalent d'Haiku) pour ses sous-agents. Le mapping s'effectue par variables d'environnement, comme nous le détaillerons plus loin.
5. Performance réelle : où se situe DeepSeek-V4 sur les benchmarks ?
C'est sur ce point que la lecture des chiffres demande le plus de rigueur. Les communications de presse de DeepSeek annoncent des performances « rivalisant avec les meilleurs modèles fermés ». Les benchmarks indépendants apportent une nuance importante.
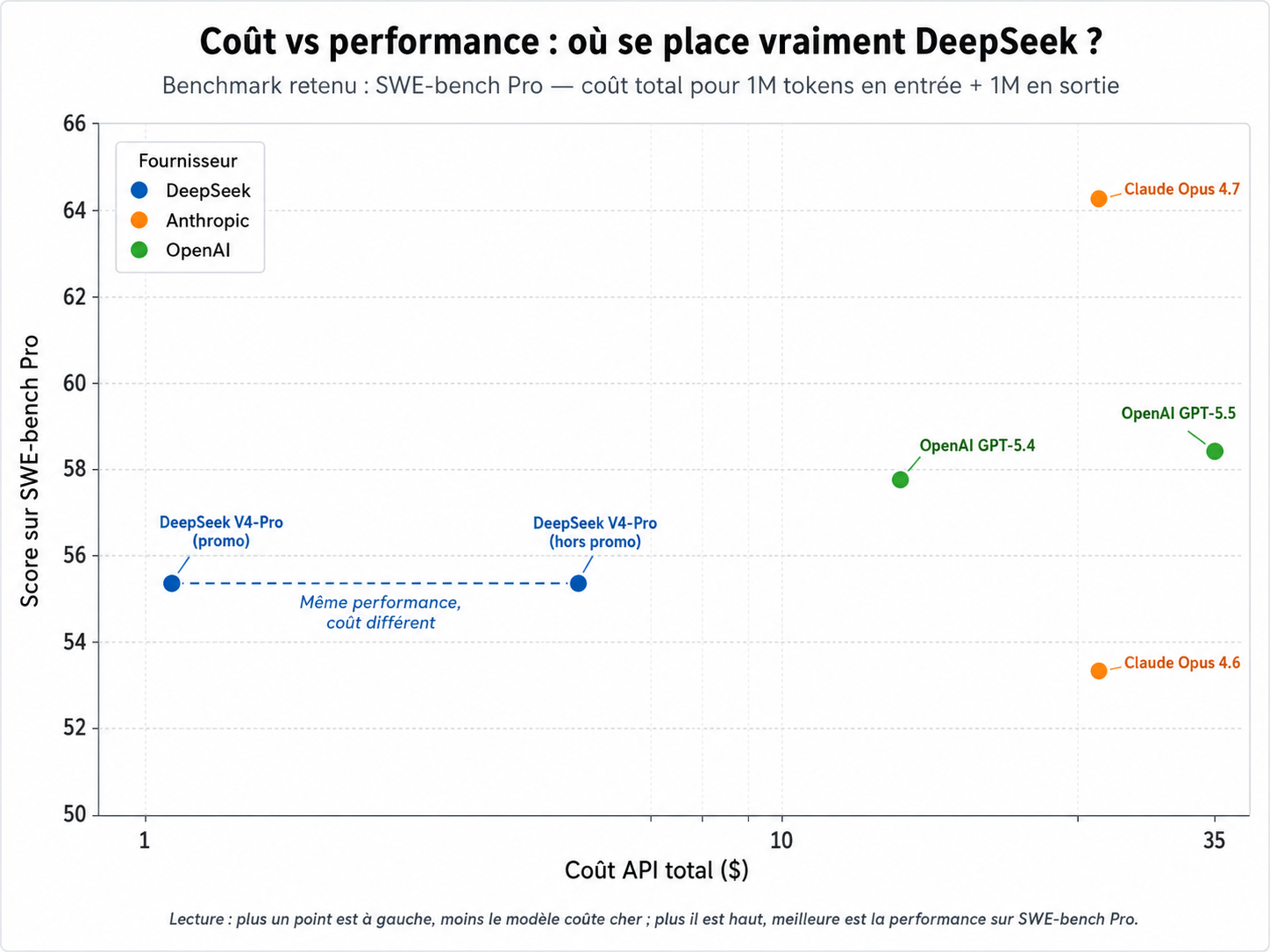
L'axe horizontal représente le coût total de l'API en dollars (échelle logarithmique, de 1 $ à 35 $) pour traiter 1 million de tokens en entrée et 1 million en sortie. L'axe vertical représente le score sur SWE-bench Pro, le benchmark de référence pour les tâches de codage agentique. Idéalement, un modèle devrait être en haut à gauche : haute performance, coût bas.
Ce graphique livre quatre enseignements précis.
Premièrement, Claude Opus 4.7 reste le modèle le plus performant en absolu sur ce benchmark, avec 64,3 points. C'est environ 9 points devant DeepSeek-V4-Pro (55,4). Ce différentiel est significatif et il faut le reconnaître honnêtement : sur les tâches de raisonnement les plus exigeantes, Opus 4.7 conserve une avance mesurable.
Deuxièmement, DeepSeek-V4-Pro se situe au niveau de Claude Opus 4.6 (53,4) et légèrement en dessous de OpenAI GPT-5.4 (57,7). On parle donc d'un modèle compétitif avec la génération précédente des modèles fermés haut de gamme, et avec les versions intermédiaires de la génération actuelle.
Troisièmement, et c'est l'enseignement central du graphique, DeepSeek-V4-Pro est horizontalement décalé vers la gauche par rapport à tous ses concurrents directs. Le ligne pointillée qui relie les deux points de V4-Pro (tarif promotionnel et tarif standard) illustre que la performance est constante quel que soit le tarif applicable, mais que le coût varie d'un facteur 4. À tarif promotionnel, V4-Pro coûte environ 1,30 $ pour ce volume de requêtes, contre 30 $ pour Opus 4.7. À tarif standard, le coût monte à 5,22 $, soit toujours moins du sixième du prix de l'option Anthropic.
Quatrièmement, OpenAI GPT-5.5 occupe la position la plus défavorable du graphique. À 35 $ pour le même volume de requêtes, il est plus cher qu'Opus 4.7 mais moins performant (58,4 contre 64,3). Cette position rappelle un principe simple : le modèle le plus cher du marché n'est pas toujours le meilleur, et la position relative sur le plan coût-performance évolue à chaque génération.
La conclusion n'est pas que DeepSeek-V4-Pro « bat » Opus 4.7. Ce n'est pas vrai. La conclusion est que pour la grande majorité des tâches de codage qui ne nécessitent pas le tout dernier point de performance, le ratio coût-performance change de classe.
Le détail des prix
Pour quantifier précisément l'écart économique, il faut décomposer la structure tarifaire. Les API de modèles facturent séparément les tokens d'entrée (le prompt envoyé) et les tokens de sortie (la réponse générée), avec des prix généralement très différents — la sortie coûte typiquement 3 à 5 fois plus cher que l'entrée.
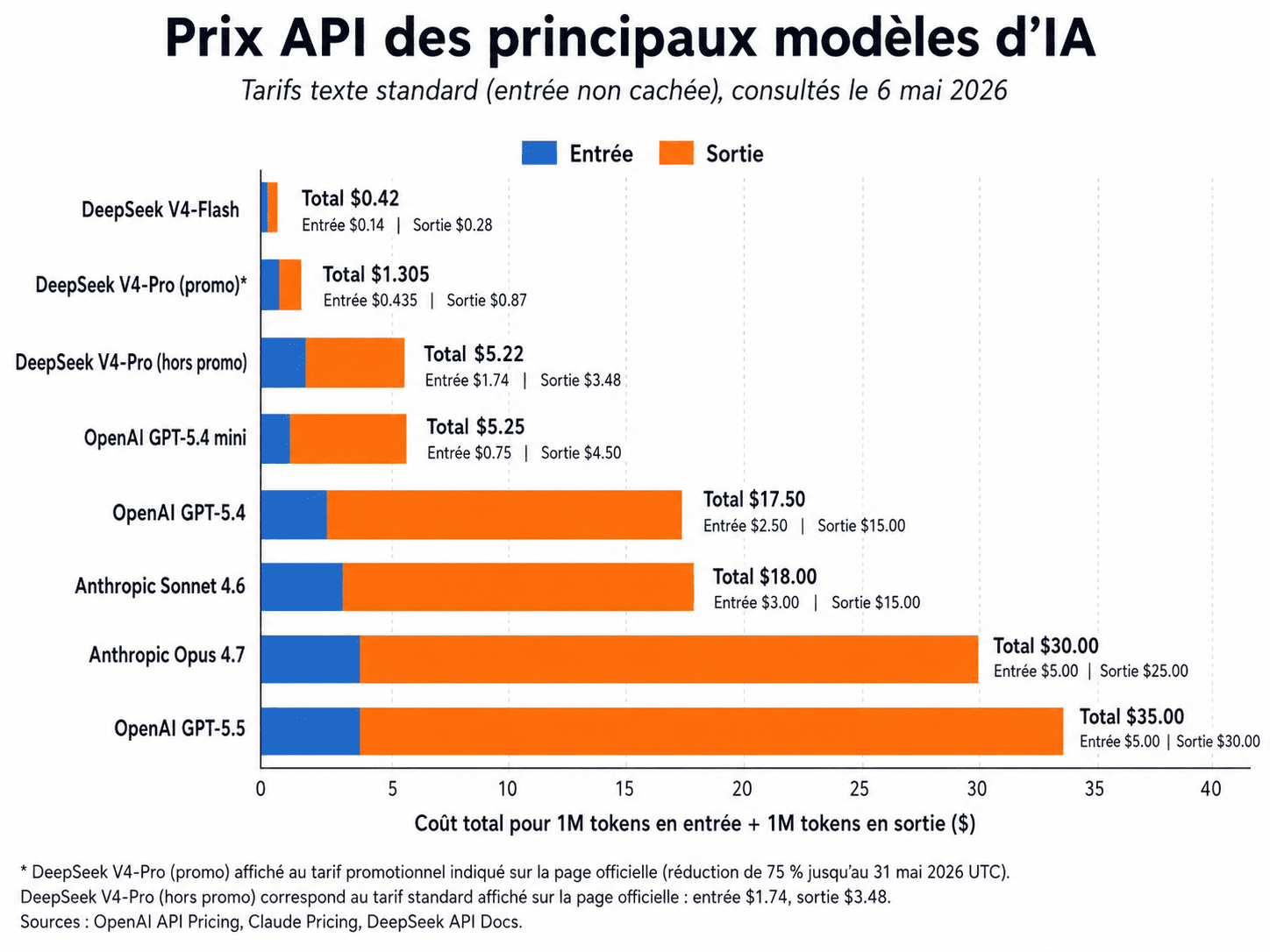
Chaque barre représente le coût total pour 1 million de tokens en entrée plus 1 million de tokens en sortie, soit le volume typique d'une session de développement de plusieurs heures. La barre est segmentée en deux : la portion bleue représente le coût d'entrée, la portion orange le coût de sortie. Le total apparaît en gras à droite de chaque barre.
L'analyse de cette grille tarifaire révèle plusieurs structures intéressantes.
D'abord, le marché se segmente clairement en quatre niveaux de prix. Les modèles ultra-économiques sous 1 $ (DeepSeek-V4-Flash à 0,42 $). Les modèles premium-économiques entre 1 et 6 $ (DeepSeek-V4-Pro en promotion à 1,30 $, V4-Pro standard à 5,22 $, OpenAI GPT-5.4 mini à 5,25 $). Les modèles haut de gamme entre 17 et 18 $ (OpenAI GPT-5.4 à 17,50 $, Anthropic Sonnet 4.6 à 18 $). Et les modèles ultra-premium au-dessus de 30 $ (Anthropic Opus 4.7 à 30 $, OpenAI GPT-5.5 à 35 $).
Ensuite, on remarque que le ratio sortie/entrée n'est pas le même partout. Chez Anthropic, ce ratio est constant à 5× (5 $ d'entrée pour 25 $ de sortie sur Opus 4.7). Chez OpenAI, le ratio sur GPT-5.4 est de 6× (2,50 $ contre 15 $), tandis que sur GPT-5.4 mini, il monte à 6× également mais sur des bases plus basses. Chez DeepSeek, le ratio sortie/entrée est de seulement 2× (1,74 $ d'entrée pour 3,48 $ de sortie sur V4-Pro standard). Cette différence est importante pour les workflows agentiques, qui sont par nature très productifs en tokens de sortie : plus le ratio sortie/entrée du fournisseur est faible, plus l'avantage économique est élevé sur ces workflows.
Enfin, la promotion en cours sur DeepSeek-V4-Pro (réduction de 75 % jusqu'au 31 mai 2026) crée une situation transitoire mais exploitable. À 1,305 $ pour le volume de référence, V4-Pro revient à environ 4,4 % du coût d'Opus 4.7. Même au tarif standard post-promotion, à 5,22 $, l'écart reste de 5,7×.
Il faut noter que ces tarifs s'appliquent aux requêtes non cachées. Les deux fournisseurs offrent des tarifs réduits sur les hits de cache (entrée déjà transmise dans une requête récente), mais DeepSeek propose des tarifs particulièrement agressifs : environ 0,003 $ par million de tokens en cache, contre 0,30 $ chez Anthropic. Sur des sessions agentiques longues où le contexte se répète massivement, l'effet du cache peut diviser encore le coût total par 5 à 10.
7. Du tarif abstrait au coût réel par tâche
Les chiffres « par million de tokens » constituent la convention standard de l'industrie, mais ils restent abstraits pour qui ne manipule pas régulièrement les ordres de grandeur de la consommation token. Une étape de concrétisation est nécessaire : combien coûte, en pratique, chaque type d'interaction qu'un développeur exécute dans une journée normale de travail ?
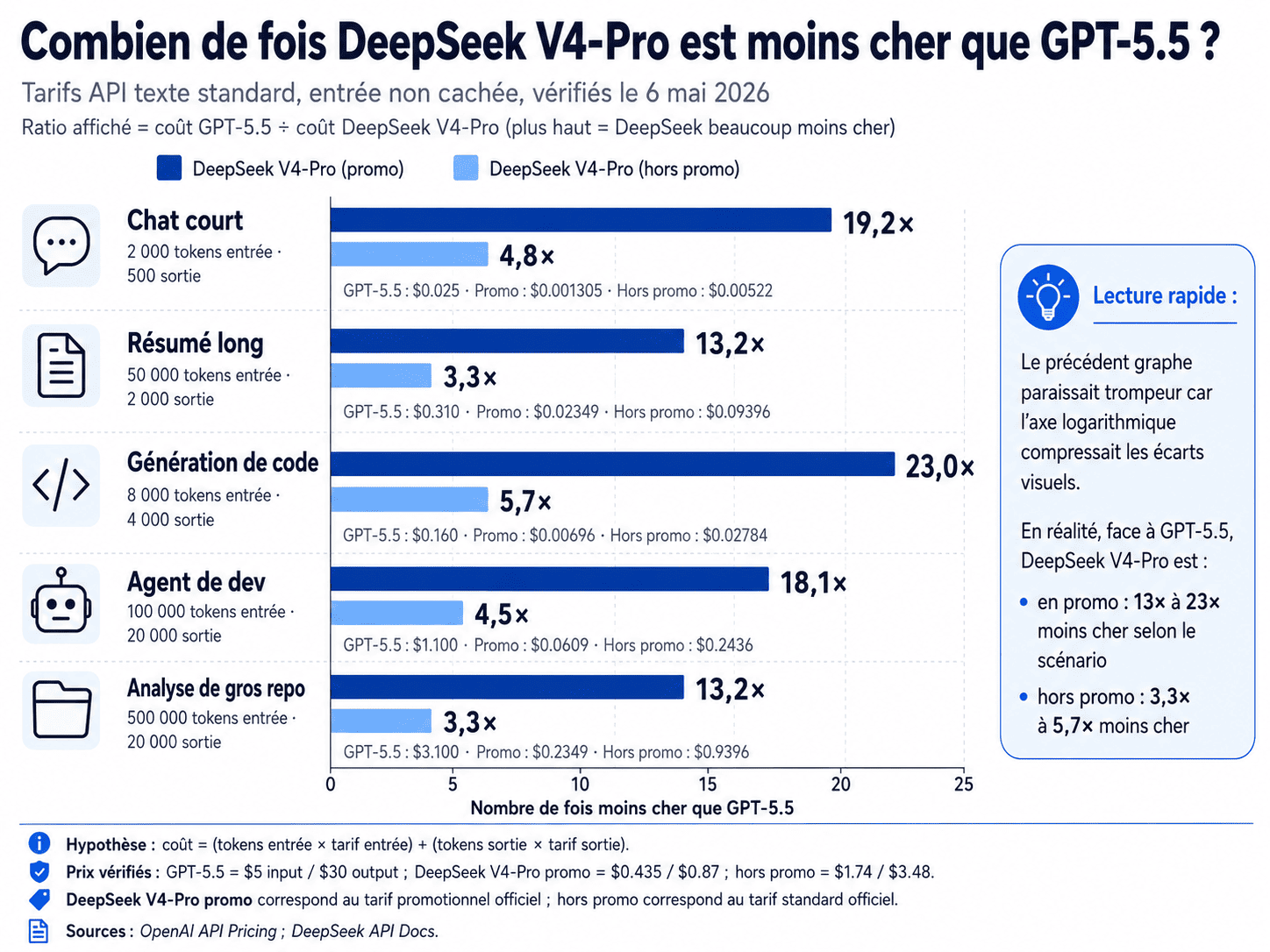
L’axe vertical liste cinq scénarios calibrés sur des volumes de tokens représentatifs de cas réels. L’axe horizontal ne donne pas le coût en dollars : il donne le ratio coût GPT-5.5 ÷ coût DeepSeek V4-Pro. Plus la barre est longue, plus DeepSeek V4-Pro est moins cher que GPT-5.5. Le graphique compare uniquement deux hypothèses tarifaires pour DeepSeek V4-Pro : le tarif promotionnel et le tarif standard hors promotion.
Cette présentation révèle quatre propriétés importantes.
Premièrement, l’écart relatif est massif dans tous les scénarios. Au tarif standard hors promotion, DeepSeek V4-Pro est entre 3,3 et 5,7 fois moins cher que GPT-5.5. Au tarif promotionnel, l’écart monte entre 13,2 et 23 fois selon le profil de requête. Cela signifie que l’avantage tarifaire ne dépend pas d’un cas isolé : il reste visible sur un chat court, un résumé long, une génération de code, une boucle agentique et une analyse de gros repository.
Deuxièmement, le profil entrée/sortie modifie fortement le ratio. Le scénario le plus favorable à DeepSeek V4-Pro est la génération de code, avec 8 000 tokens d’entrée et 4 000 tokens de sortie : GPT-5.5 coûte 0,160 $, contre 0,02784 $ pour DeepSeek V4-Pro hors promotion et 0,00696 $ en promotion. Le ratio atteint donc 5,7 fois hors promotion et 23 fois en promotion. Cela vient du fait que GPT-5.5 facture particulièrement cher les tokens de sortie.
Troisièmement, les scénarios à très gros contexte restent très avantageux, mais avec un ratio plus bas. Pour l’analyse d’un gros repository, avec 500 000 tokens d’entrée et 20 000 tokens de sortie, GPT-5.5 coûte 3,10 $, contre 0,9396 $ pour DeepSeek V4-Pro hors promotion et 0,2349 $ en promotion. Le ratio est donc de 3,3 fois hors promotion et 13,2 fois en promotion. L’économie relative est moins spectaculaire que sur la génération de code, mais l’économie absolue devient beaucoup plus importante en dollars.
Quatrièmement, le scénario « Agent de dev » illustre bien l’intérêt économique pour un usage de type Claude Code, Codex ou agent de développement connecté à un projet. Avec 100 000 tokens d’entrée et 20 000 tokens de sortie, GPT-5.5 coûte 1,10 $ par requête, contre 0,2436 $ pour DeepSeek V4-Pro hors promotion et 0,0609 $ en promotion. Sur une session de cinquante itérations, cela représente environ 55 $ avec GPT-5.5, 12,18 $ avec DeepSeek V4-Pro hors promotion, et seulement 3,05 $ avec le tarif promotionnel.
La conclusion est donc plus nette que dans une simple grille tarifaire : face à GPT-5.5, DeepSeek V4-Pro n’est pas seulement moins cher sur le papier. Il est structurellement moins cher sur des scénarios concrets, avec un avantage de 3,3 à 5,7 fois hors promotion, et de 13,2 à 23 fois au tarif promotionnel. La vraie question économique n’est donc plus seulement le prix brut, mais le rapport entre ce prix et la performance effective du modèle sur les tâches de développement.
8. La métrique décisive : performance par dollar dépensé
Les deux graphiques précédents — performance brute et coût brut — sont intéressants pris séparément, mais c'est leur combinaison qui guide la décision rationnelle. La métrique « score SWE-bench Pro par dollar dépensé » synthétise les deux dimensions en un seul nombre.
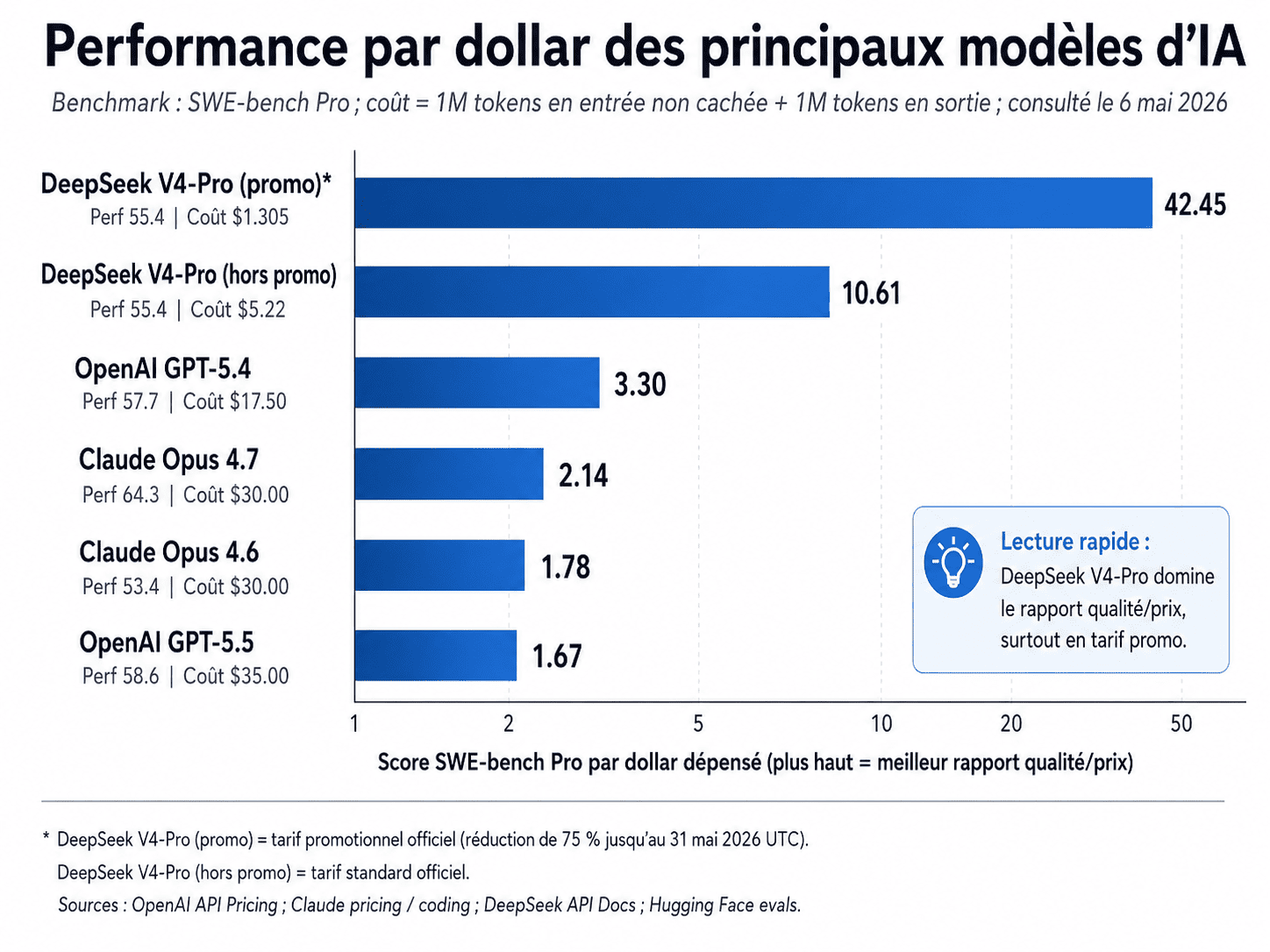
Chaque barre représente le score SWE-bench Pro divisé par le coût en dollars (plus la barre est longue, meilleur est le rapport qualité/prix). L'axe horizontal est en échelle logarithmique pour rendre lisible un éventail qui va de 1,67 à 42,45. La règle de lecture est simple : un modèle deux fois plus à droite qu'un autre offre deux fois plus de performance par dollar.
Trois conclusions se dégagent de cette présentation.
La première est que DeepSeek-V4-Pro à tarif promotionnel atteint un ratio de 42,45 points par dollar, soit environ 20 fois supérieur à celui d'Opus 4.7 (2,14). Cet écart est sans précédent à ce niveau de qualité. Aucun modèle commercial n'avait jusqu'ici proposé un ordre de grandeur de différence sur cette métrique tout en restant dans la zone des modèles compétents pour le code agentique.
La deuxième est que même hors promotion, à 10,61 points par dollar, V4-Pro reste presque 5× plus efficient qu'Opus 4.7. Cette efficience standard est la plus pertinente pour planifier un budget d'équipe à long terme : la promotion de juin va expirer, mais la structure tarifaire de fond, elle, restera durablement avantageuse.
La troisième est que OpenAI GPT-5.5, malgré son positionnement haut de gamme, occupe le bas du classement à 1,67 points par dollar. Cela signifie qu'à budget équivalent, on obtient plus d'utilité du benchmark SWE-bench Pro sur n'importe quel autre modèle. La situation de GPT-5.5 illustre un piège classique des modèles ultra-premium : ils maximisent la performance brute mais détruisent l'efficience.
Il faut toutefois interpréter cette métrique avec prudence. La performance par dollar ne capture pas le coût d'opportunité d'un raisonnement raté. Si une tâche critique nécessite les 9 points d'avance d'Opus 4.7 pour aboutir au premier essai au lieu de devoir itérer trois fois sur un modèle moins puissant, alors le calcul brut est trompeur. Cette nuance est précisément l'objet de la section 13.
Le mécanisme technique : la couche de compatibilité Anthropic
Pour comprendre pourquoi cette substitution de modèle ne nécessite aucune modification de Claude Code, il faut examiner la nature exacte de la communication entre l'agent et son modèle.
Claude Code envoie ses requêtes via le format standard de l'API Anthropic, dont la structure est la suivante :
POST https://api.anthropic.com/v1/messages
Content-Type: application/json
x-api-key: sk-ant-...
{
"model": "claude-opus-4-7",
"max_tokens": 4000,
"system": "...",
"messages": [
{"role": "user", "content": "..."},
...
],
"tools": [...]
}
DeepSeek a répliqué cette signature à l'identique sur l'endpoint https://api.deepseek.com/anthropic. Lorsque Claude Code voit son ANTHROPIC_BASE_URL redirigé, il continue à émettre exactement les mêmes requêtes, mais celles-ci atteignent les serveurs DeepSeek. À l'arrivée, le serveur DeepSeek traduit la requête vers son propre format interne, exécute l'inférence sur V4-Pro ou V4-Flash, puis re-encode la réponse au format Anthropic pour la renvoyer. Cette traduction est entièrement invisible côté client.
La portée de cette compatibilité va au-delà de Claude Code. Le SDK @anthropic-ai/sdk officiel, n'importe quelle bibliothèque tierce écrite pour Claude, et tout outil interne qu'une équipe aurait construit autour du protocole Anthropic, fonctionnent sans modification. C'est la définition même d'une compatibilité de protocole.
Cette stratégie de compatibilité descendante n'est pas nouvelle dans l'histoire des plateformes : OpenAI avait fait la même chose avec son format ChatCompletions, devenu le quasi-standard de l'industrie en 2023-2024. DeepSeek joue maintenant la même partition autour du protocole Anthropic, avec un objectif tactique clair : permettre la migration sans friction depuis l'écosystème Claude.
Installation et prérequis
L'installation se déroule en quatre étapes bien délimitées.
Mais d'abord allez sur https://platform.deepseek.com/ pour créer un compte, générer une clé d'API et mettre au minimum 5$ ce qui sera largement suffisant pour bien tester !
Prérequis. Node.js 18 ou supérieur. Sur Windows, Git for Windows est nécessaire pour les utilitaires shell utilisés par Claude Code. Une clé API valide sur la plateforme DeepSeek (créable depuis platform.deepseek.com après inscription).
Installation de Claude Code. L'installation officielle passe par npm :
npm install -g @anthropic-ai/claude-code
Vérification que le binaire est correctement installé et accessible dans le PATH :
claude --version
Pour les utilisateurs préférant éviter une installation Node.js globale, Anthropic propose un installateur natif :
# macOS / Linux / WSL
curl -fsSL https://claude.ai/install.sh | bash
# Windows PowerShell
irm https://claude.ai/install.ps1 | iex
Configuration de l'environnement (macOS, Linux, WSL). Les variables suivantes doivent être définies dans le fichier de configuration du shell (~/.zshrc, ~/.bashrc, ou équivalent) pour persister entre les sessions :
export ANTHROPIC_BASE_URL="https://api.deepseek.com/anthropic"
export ANTHROPIC_AUTH_TOKEN="<votre_clé_api_deepseek>"
export ANTHROPIC_MODEL="deepseek-v4-pro[1m]"
export ANTHROPIC_DEFAULT_OPUS_MODEL="deepseek-v4-pro[1m]"
export ANTHROPIC_DEFAULT_SONNET_MODEL="deepseek-v4-pro[1m]"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="deepseek-v4-flash"
export CLAUDE_CODE_SUBAGENT_MODEL="deepseek-v4-flash"
export CLAUDE_CODE_EFFORT_LEVEL="max"
Configuration sous Windows PowerShell. Pour une persistance entre sessions, ces définitions doivent être ajoutées au profil PowerShell ($PROFILE) :
$env:ANTHROPIC_BASE_URL="https://api.deepseek.com/anthropic"
$env:ANTHROPIC_AUTH_TOKEN="<votre_clé_api_deepseek>"
$env:ANTHROPIC_MODEL="deepseek-v4-pro[1m]"
$env:ANTHROPIC_DEFAULT_OPUS_MODEL="deepseek-v4-pro[1m]"
$env:ANTHROPIC_DEFAULT_SONNET_MODEL="deepseek-v4-pro[1m]"
$env:ANTHROPIC_DEFAULT_HAIKU_MODEL="deepseek-v4-flash"
$env:CLAUDE_CODE_SUBAGENT_MODEL="deepseek-v4-flash"
$env:CLAUDE_CODE_EFFORT_LEVEL="max"
11. Comprendre chaque variable de configuration
Le rôle de chaque variable n'est pas évident, et plusieurs erreurs courantes proviennent d'une mauvaise compréhension de leur articulation.
| Variable | Rôle | Recommandation |
|---|---|---|
ANTHROPIC_BASE_URL |
URL de base de l'API. Ce paramètre est le seul qui détermine le fournisseur effectif. Sans lui, tout le reste devient inopérant. | https://api.deepseek.com/anthropic |
ANTHROPIC_AUTH_TOKEN |
Clé d'authentification. Doit correspondre au fournisseur défini dans BASE_URL. Une clé Anthropic envoyée à DeepSeek produit une erreur 401. |
Clé issue de platform.deepseek.com |
ANTHROPIC_MODEL |
Modèle par défaut pour les nouvelles sessions. Le suffixe [1m] active explicitement la fenêtre de contexte d'un million de tokens. |
deepseek-v4-pro[1m] |
ANTHROPIC_DEFAULT_OPUS_MODEL |
Modèle utilisé lorsque Claude Code aurait sélectionné Opus. Pour conserver la qualité de raisonnement, on redirige vers V4-Pro. |
deepseek-v4-pro[1m] |
ANTHROPIC_DEFAULT_SONNET_MODEL |
Modèle pour les requêtes équivalentes Sonnet. Idem. |
deepseek-v4-pro[1m] |
ANTHROPIC_DEFAULT_HAIKU_MODEL |
Modèle pour les requêtes équivalentes Haiku (rapides, fréquentes). À rediriger vers V4-Flash. |
deepseek-v4-flash |
CLAUDE_CODE_SUBAGENT_MODEL |
Modèle utilisé par les sous-agents internes (recherche dans les fichiers, classifications). V4-Flash est largement suffisant et beaucoup moins cher. |
deepseek-v4-flash |
CLAUDE_CODE_EFFORT_LEVEL |
Niveau d'effort de raisonnement. max privilégie la qualité, low la vitesse. À ajuster selon le type de tâche dominant. |
max ou medium |
Un point crucial : la coexistence d'ANTHROPIC_API_KEY (variable historique reconnue par certains outils tiers) et d'ANTHROPIC_AUTH_TOKEN peut créer des conflits subtils. Si une ancienne ANTHROPIC_API_KEY Anthropic traîne dans l'environnement, certains chemins de code peuvent encore l'utiliser silencieusement. La pratique sûre consiste soit à supprimer toute ANTHROPIC_API_KEY existante, soit à la définir avec la même clé DeepSeek. Au lancement, la commande /status dans Claude Code permet de vérifier le modèle et l'endpoint effectivement utilisés.
12. Démonstration : génération d'une API REST complète
Pour illustrer concrètement ce que produit ce setup, déroulons une session de bout en bout. Création d'un dossier vide, lancement de Claude Code, et demande de générer un projet complet.
mkdir api-todos-demo
cd api-todos-demo
claude
Remarquez bien :
Nous avons le modèle deepseek-v4-pro utilisé !
Dans l'invite de Claude Code, on transmet le cahier des charges suivant :
Crée un projet Node.js en TypeScript avec Express.
Objectif :
Construire une petite API de tâches.
Contraintes :
- Une route GET /health qui retourne { "status": "ok" }.
- Une route GET /todos qui retourne la liste des tâches.
- Une route POST /todos qui ajoute une tâche.
- Une validation simple du champ title.
- Une structure claire avec un dossier src.
- Un fichier src/server.ts.
- Un fichier src/routes/todos.ts.
- Des tests avec Vitest.
- Un README en français.
- Des commentaires en français uniquement.
- Des scripts npm run dev, npm run build et npm test.
Avant de modifier les fichiers, propose le plan de création.
Ensuite, crée les fichiers, installe les dépendances nécessaires,
lance les tests et corrige les erreurs si nécessaire.
L'agent enchaîne alors cinq phases observables.
Phase de planification. V4-Pro analyse le cahier des charges et propose une arborescence avec la liste des dépendances. À ce stade, aucune modification n'est faite sur le système de fichiers ; l'utilisateur peut valider ou amender le plan.
Phase de scaffolding. L'agent crée séquentiellement package.json, tsconfig.json, src/server.ts, src/routes/todos.ts, les fichiers de tests et le README. Chaque création est précédée d'un diff pour transparence.
Phase d'installation. Claude Code lance directement les commandes d'installation appropriées :
npm install express
npm install -D typescript tsx vitest supertest @types/express @types/supertest
Phase de validation. L'agent exécute npm test. Si les tests échouent — typage incorrect, import manquant, configuration Vitest incomplète — V4-Pro lit la sortie d'erreur, identifie la cause et applique un correctif sans intervention humaine.
Phase de vérification fonctionnelle. L'agent propose npm run dev et suggère des commandes curl pour valider le bon fonctionnement de l'API en conditions réelles :
curl http://localhost:3000/health
curl -X POST http://localhost:3000/todos \
-H "Content-Type: application/json" \
-d '{"title":"Tester DeepSeek avec Claude Code"}'
Ce cycle plan-action-observation-correction est précisément ce qui distingue un agent d'un assistant de complétion. Et c'est ce cycle qui tourne désormais sur l'infrastructure DeepSeek au lieu d'Anthropic, pour un coût qui se chiffre en dizaines de centimes plutôt qu'en dollars.
13. Utilisation directe de l'API via le SDK Anthropic
Pour vérifier la compatibilité de protocole indépendamment de Claude Code, on peut appeler DeepSeek directement via le SDK @anthropic-ai/sdk. Cette démonstration est utile pour comprendre que la compatibilité opère au niveau du protocole, pas au niveau de l'outil.
mkdir test-sdk-anthropic-deepseek
cd test-sdk-anthropic-deepseek
npm init -y
npm install @anthropic-ai/sdk dotenv
npm install -D tsx typescript
Configuration via .env :
ANTHROPIC_BASE_URL="https://api.deepseek.com/anthropic"
ANTHROPIC_API_KEY="votre_clé_api_deepseek"
Script de test :
import "dotenv/config";
import Anthropic from "@anthropic-ai/sdk";
// SDK Anthropic, mais redirigé vers DeepSeek via baseURL
const client = new Anthropic({
apiKey: process.env.ANTHROPIC_API_KEY,
baseURL: process.env.ANTHROPIC_BASE_URL,
});
async function main() {
const message = await client.messages.create({
model: "deepseek-v4-pro",
max_tokens: 1000,
system:
"Tu es un assistant développeur. Tu réponds en français, " +
"de manière concise et technique.",
messages: [
{
role: "user",
content:
"Génère une fonction TypeScript qui valide une adresse email " +
"simple, avec un exemple d'utilisation.",
},
],
});
console.log(message.content);
}
main().catch((erreur) => {
console.error("Erreur pendant l'appel API :", erreur);
});
Exécution :
npx tsx test-sdk-anthropic-deepseek.ts
Le SDK Anthropic traite cette requête comme n'importe quelle autre et reçoit une réponse parfaitement formatée selon ses attentes. La seule différence avec un usage standard est l'identifiant du modèle (deepseek-v4-pro au lieu d'claude-opus-4-7) et l'URL de base, redirigée par la variable d'environnement.
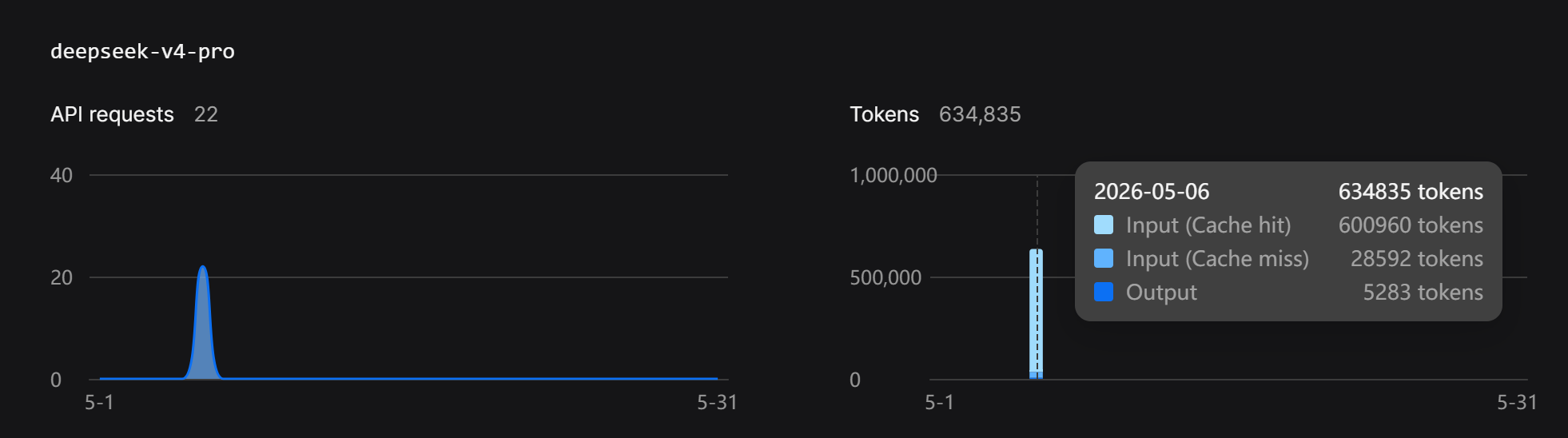
Après la mini-app et l'utilisation de l'API nous en sommes à 0.01$ de coût et voici l'utilisation en tokens :
14. Analyse stratégique : quand cette configuration est rationnelle, et quand elle ne l'est pas
Aucune décision technologique n'est universellement optimale. La question n'est pas « est-ce que DeepSeek-V4 est meilleur que Claude », mais « pour quelle catégorie de tâches le couple Claude Code × V4-Pro constitue-t-il l'optimum coût-utilité ? ».
Cas où la configuration est clairement optimale. Les sessions agentiques longues de plusieurs heures sur des projets de taille moyenne, où le cache se remplit rapidement et où le coût marginal par requête devient quasi-nul. Les tâches de refactoring volumineuses, où les itérations massives sur un gros volume de code rendraient l'usage d'Opus 4.7 économiquement difficile à justifier. Les workflows d'audit ou d'analyse où la fenêtre d'un million de tokens permet d'absorber l'intégralité d'une base de code sans découpage. Les contextes pédagogiques où des juniors ou des étudiants doivent pouvoir itérer librement sans surveillance budgétaire.
Cas où Opus 4.7 reste préférable. Les tâches de raisonnement à la frontière de l'état de l'art — résolution de bugs de concurrence retors, conception d'algorithmes nouveaux, analyse de code à très haute densité conceptuelle — où les 9 points d'avance sur SWE-bench Pro se traduisent par une réduction tangible du nombre d'itérations nécessaires. Les contextes où le coût d'une erreur est élevé (production critique, code de sécurité), parce que le coût d'opportunité d'un mauvais raisonnement dépasse largement l'écart d'API.
Cas où des considérations non économiques dominent. La confidentialité des données traitées : DeepSeek ne propose pas, à la date de cet article, de mécanisme d'opt-out aussi explicite qu'Anthropic en matière d'utilisation des conversations pour l'entraînement futur. Pour des données sensibles régulées (santé, défense, propriété intellectuelle stratégique), cette absence de garantie peut être disqualifiante, indépendamment du gain économique. Une voie intermédiaire consiste à utiliser des hébergeurs tiers (OpenRouter, Fireworks AI, Together AI) qui exposent les poids open-source de V4 sous une politique de non-utilisation des données client.
Cas où la latence est dimensionnante. Les serveurs DeepSeek sont principalement localisés en Asie. Pour un développeur basé en Europe ou en Amérique, le RTT ajoute un délai mesurable à chaque requête, qui devient perceptible en mode interactif intensif. Les hébergeurs tiers régionaux (US, EU) constituent une réponse technique, au prix d'un coût intermédiaire entre DeepSeek direct et Anthropic.
15. Pièges de configuration les plus fréquents
L'expérience accumulée par la communauté depuis la sortie de V4 permet de cataloguer les erreurs récurrentes. Cinq se détachent particulièrement.
Omission du suffixe [1m] dans le nom du modèle. Sans ce suffixe, deepseek-v4-pro est interrogé avec la fenêtre de contexte par défaut, plus courte. L'agent perd alors la mémoire conversationnelle au-delà de quelques milliers de tokens, ce qui se manifeste par des oublis incohérents et des reprises de raisonnement incomplètes.
Confusion entre ANTHROPIC_API_KEY et ANTHROPIC_AUTH_TOKEN. Claude Code lit prioritairement ANTHROPIC_AUTH_TOKEN, tandis que le SDK officiel lit ANTHROPIC_API_KEY. Définir les deux avec la même valeur (DeepSeek) est la pratique la plus sûre.
Persistance d'une ANTHROPIC_API_KEY Anthropic dans l'environnement. Cette variable peut subsister silencieusement dans une configuration de shell ancienne, et certains chemins de code peuvent encore la consulter. Le développeur croit alors interroger DeepSeek, mais une partie de son trafic continue à atteindre Anthropic. La commande /status au lancement de Claude Code permet de vérifier l'endpoint et le modèle réellement utilisés.
Sur-allocation de l'effort de raisonnement sur V4-Flash. CLAUDE_CODE_EFFORT_LEVEL=max combiné à un modèle V4-Flash est inefficient : Flash n'est pas conçu pour des raisonnements longs, et l'effort élevé ne fait qu'augmenter le coût sans amélioration significative de la qualité. Pour les sous-agents V4-Flash, le niveau low ou medium est généralement plus rationnel.
Sous-estimation de l'effet du cache dans les benchmarks de coût. Comparer le coût de plusieurs modèles en lançant plusieurs sessions courtes successives produit des chiffres trompeurs, parce que le cache n'a pas le temps de se remplir. Pour évaluer correctement le coût en production, il faut mesurer sur des sessions longues représentatives, où le contexte se stabilise et où le tarif effectif descend significativement sous le tarif facial.
16. Implications stratégiques : la fin du couplage outil-modèle
Au-delà de l'aspect tactique de la réduction des coûts, la vraie portée de cette bascule est structurelle. Pendant deux ans, le marché de l'IA pour développeurs s'est construit sur une hypothèse implicite : choisir un outil revient à choisir un modèle, et inversement. Cette hypothèse est en train de se dissoudre.
La compatibilité de protocole rend les couches outil et modèle indépendantes au sens technique. Claude Code peut parler à Claude, à DeepSeek, à OpenRouter, à un modèle local servi par Ollama configuré pour exposer le format Anthropic, ou à n'importe quel fournisseur futur qui adoptera la même interface. Symétriquement, DeepSeek-V4 peut être consommé depuis Claude Code, depuis Cursor (via l'API compatible OpenAI), depuis OpenCode, depuis OpenClaw, ou depuis n'importe quel client construit sur le SDK Anthropic ou OpenAI.
Ce découplage modifie la nature même du choix technologique. Là où il fallait auparavant arbitrer entre deux écosystèmes complets, on peut désormais arbitrer indépendamment l'outil de développement (selon son ergonomie, sa puissance d'agent, son intégration à l'IDE) et le modèle d'inférence (selon la qualité, le coût, la confidentialité, la latence régionale). Les deux décisions deviennent quasi-orthogonales.
Pour les équipes, cela ouvre des stratégies hybrides précédemment impossibles. Utilisation de V4-Flash pour les 80 % de tâches simples (recherche, classification, refactoring trivial) et bascule vers Opus 4.7 ponctuellement pour les 20 % qui exigent le top de la performance. Politique différenciée par dépôt — modèle économique sur les projets internes, modèle premium sur les composants critiques. Bascule en cours de session, comme le permet DeepClaude avec ses commandes slash, pour ajuster dynamiquement le ratio coût-qualité au type de tâche en cours.
Pour le marché, l'effet est encore plus profond. Les fournisseurs de modèles ne peuvent plus capturer leurs utilisateurs par la qualité de leur outillage propriétaire si les outils dominants deviennent compatibles multi-fournisseurs. La pression concurrentielle sur les prix s'intensifie mécaniquement. Anthropic peut soit baisser ses tarifs pour défendre sa part de marché sur l'API, soit mettre en avant des fonctionnalités qui restent attachées à ses modèles spécifiques (par exemple des skills propriétaires, des intégrations entreprise, des garanties de confidentialité contractuelles). Les deux mouvements sont probablement à attendre dans les mois qui viennent.
17. Conclusion
Le couple Claude Code × DeepSeek-V4 n'est pas, à proprement parler, une nouveauté technologique. C'est l'application précise d'un principe d'ingénierie ancien — l'interopérabilité des protocoles — à un domaine où ce principe avait été mis entre parenthèses pendant deux ans. La nouveauté est dans le timing : c'est la première fois qu'un modèle ouvert atteint une qualité suffisante sur les benchmarks de codage agentique tout en exposant le bon protocole, au moment exact où l'outillage agentique côté client atteint sa maturité.
Pour le développeur, la conséquence pratique est simple. Trois variables d'environnement permettent désormais de réduire d'un facteur 5 à 20 le coût d'une session de codage agentique sans changer un seul aspect de son environnement de travail. Ce gain n'est pas marginal : sur une équipe de dix développeurs travaillant en agentique plusieurs heures par jour, l'écart annuel se chiffre en dizaines de milliers de dollars.
Pour le manager technique, la question n'est plus « quel modèle adopter », mais « quelle architecture de routage entre modèles mettre en place selon la criticité de chaque type de tâche ». Le choix unique est devenu un choix continu.
Et pour le marché de l'IA, le signal est que la phase d'intégration verticale touche à sa fin. La phase suivante — la coexistence de couches modulaires concurrentes au-dessus de protocoles standards — est déjà commencée. Les gagnants ne seront pas ceux qui vendent le meilleur modèle dans le meilleur outil, mais ceux qui auront compris en premier que ces deux décisions sont, désormais, deux décisions distinctes.



